Abstract
As AI agents mature, the communication layer—how humans and AI systems interact—becomes the critical differentiator. Building on our three-layer architecture (Constructive Thinking, Communication, Execution) and GTUI principles, we examine seven distinct interface patterns that have emerged across the AI landscape. From canvas-based visual workflows to headless automation, each pattern represents a different philosophy about how humans should direct AI capabilities. Through analysis of real implementations—youpac.dev's video workflow canvas, SmythOS's universal builder, embedded chat experiences, and dynamic split-screen interfaces—we reveal how the choice of interface pattern fundamentally shapes what's possible in human-AI collaboration. The diversity of approaches confirms a crucial insight: there is no one-size-fits-all solution for AI interfaces. Instead, we're witnessing the emergence of a pattern language where each approach excels in specific contexts.
Introduction: The Communication Layer in Practice
In our exploration of Software 3.0's three-layer architecture, we identified Communication as the critical middle layer where human intent transforms into AI action. This layer, sandwiched between Constructive Thinking (world knowledge) and Execution (tool orchestration), determines not just how we interact with AI agents, but what we can achieve together.
Top Layer: Constructive Thinking
The top layer contains world knowledge—the principles and instructions that define how the world works and how tools operate within it. This layer sets the overarching context of what's possible for the agent and encodes domain expertise as principles. It provides instructions for tool usage, establishes boundaries and constraints, and defines patterns and relationships. World knowledge isn't just documentation—it's the accumulated understanding that makes intelligent action possible.
Middle Layer: Communication
The communication layer is where planning happens. Here, the Operator communicates goals, intentions, and situational context while providing expected outputs and success criteria. The Agent uses world knowledge from the top layer combined with its LLM capabilities to create plans. Questions are asked, clarifications made, and plans confirmed through multimodal interfaces that enable rich interaction including text, voice, image, and interactive elements. This layer is fundamentally collaborative—a negotiation toward shared understanding.
Ground Layer: Execution
The execution layer is where plans become reality through collaboration. The Agent executes the plan using available tools while the Operator acts as an additional tool, providing real-time feedback, screenshots and logs, explanations of what they see when the Agent has limited visibility, and course corrections. The Operator monitors execution and can request return to the communication layer, with adjustments to plan, context, or expected output triggering layer transitions.
Every AI agent, whether explicitly designed or organically evolved, embodies this three-layer pattern to some degree. The top layer contains the agent's understanding of its domain—its world knowledge, principles, and instructions. The bottom layer handles actual execution through tools, APIs, and integrations. But it's the middle layer—Communication—that defines the user experience and, ultimately, the agent's utility.
GTUI (Graphical Text User Interface) emerged from recognizing that both text and graphical elements are simply different ways of constructing prompts for AI agents. A typed command and a clicked button can generate identical instructions; the choice between them is about user preference and context, not capability. This insight liberates us from the false dichotomy of "chat vs GUI" and opens the door to multimodal interfaces that adapt to how humans naturally work.
Today, we're witnessing an explosion of interface experiments as developers grapple with this newfound freedom. Some embrace visual metaphors, others enhance familiar patterns, and a few abandon interfaces entirely. Each approach reveals something important about the relationship between interface design and AI capability.
Let's examine these patterns in practice, starting with one of the most visually distinctive: the canvas interface. Unlike Cursor, which most readers know well, or Claude Code, which chose the path of pure text, these implementations explore the full spectrum of multimodal possibility.
Canvas: When Workflows Become Visual
youpac.dev: The Video Creator's Canvas
The service youpac.dev by @rasmickyy represents one of the most intuitive implementations of canvas-based AI interfaces. Canvas interfaces have a rich heritage—from Miro (formerly Realtimeboard) which pioneered infinite canvas technology a decade ago using Flash game engines, to n8n's workflow automation. But youpac.dev applies this pattern specifically to video content creation, revealing how spatial arrangement can make complex AI workflows accessible.
Each element on the canvas is a "bubble"—a self-contained unit that combines source material with agent capabilities. The genius lies in the simplicity: a video bubble contains not just the video file but an implicit prompt instructing the agent to transcribe it when connected to downstream processes. A title generator bubble knows to expect transcription input and produce optimized titles. The connections between bubbles aren't just visual—they define the data flow and transformation pipeline.
What makes this implementation particularly elegant is the dual nature of each bubble. Users can interact with individual agents through chat interfaces, asking for regeneration or specific modifications, while maintaining the visual overview of the entire workflow. The side panel reveals the final result—in this case, a YouTube-ready video with AI-generated thumbnail and title, ready for posting across platforms.
This isn't just a pretty visualization—it's a fundamental rethinking of how we orchestrate AI agents. The canvas makes the invisible visible: data flows, transformation steps, and decision points all exist in space rather than time. Users can see their entire creative process at once, modify any step without losing context, and most importantly, understand what the AI system is doing at each stage.
SmythOS: The Universal Agent Builder
SmythOS takes the canvas metaphor into the realm of complex agent orchestration. The screenshot reveals "Agent Weaver"—an AI agent that can itself create other agents based on natural language descriptions. This meta-level capability transforms SmythOS from a workflow tool into an agent generation platform.
The visual complexity immediately stands out. Unlike youpac.dev's focused workflow, SmythOS embraces intricate node networks with multiple connection types, color-coded pathways, and dense information display. Each node represents not just a transformation step but a complete agent capability—from video generation to speech synthesis, from web scraping to format conversion.
What's particularly striking is how the canvas handles branching logic and parallel processes. The connections fork and merge, creating decision trees and conditional flows that would be nearly impossible to understand in a purely textual format. The visual representation makes complex agent behavior comprehensible at a glance.
The left sidebar reveals another layer: pre-built agent templates organized by capability. This combination of visual programming and template library accelerates agent creation—users can start with a working example and modify it visually rather than coding from scratch.
SmythOS demonstrates that canvas interfaces scale beyond simple workflows. When building systems that coordinate multiple AI agents, visual representation becomes essential. The canvas doesn't just display the workflow—it becomes the primary interface for understanding and controlling distributed AI systems.
Creati AI: Visual Clarity for Content Creation
Creati AI demonstrates how canvas interfaces excel when the creative process itself is inherently visual. Their implementation for fashion and lifestyle content creation makes the remixing process transparent and intuitive.
The interface presents a deceptively simple equation: combine a model, an object (clothing or accessory), and a scene to generate professional fashion photography. But the elegance lies in the visual presentation. Each element—model selection, product choice, scene setting—exists as a visual node that users can swap with a click.
What makes this implementation particularly powerful is the immediate visual feedback. The left panel shows the generated result in real-time, while the right panel maintains the component breakdown. Users can see exactly how changing from Model 1 to Model 2, or switching from a burgundy dress to a pink handbag, transforms the final image. The selected elements (marked with yellow dots and X symbols) make the current configuration immediately apparent.
This tight feedback loop transforms AI image generation from a guessing game into a controlled creative process. Fashion brands and content creators can rapidly iterate through combinations, seeing results instantly rather than crafting complex text prompts. The interface succeeds because it matches how fashion professionals think—in terms of models, products, and settings rather than technical parameters.
The real innovation here isn't just the visual interface—it's how it democratizes professional content creation. Tasks that once required photo shoots, styling teams, and post-production can now be accomplished through simple visual selection and AI generation. The canvas doesn't just display options; it embodies the creative process itself.
The Canvas Pattern: Strengths and Trade-offs
Canvas interfaces excel when workflows have clear stages, multiple inputs need orchestration, visual feedback enhances understanding, and users benefit from seeing the entire process. However, they struggle with purely textual tasks, simple single-step operations, and scenarios where the workflow itself needs to be discovered rather than defined.
The pattern reveals a deeper truth about AI interfaces: the best interface is the one that matches how users think about their problem. For video creators, content producers, and automation builders, thinking spatially about workflows is natural. The canvas doesn't impose this model—it reflects it.
Chat on a Webpage: The Familiar Made Powerful
The embedded chat pattern might seem mundane compared to visual canvases, but its familiarity is its strength. Users have been trained by decades of instant messaging and customer service interactions. When AI agents adopt this pattern, they inherit all that learned behavior.
Google's demo showcases how embedded chat transcends traditional customer service. Here, the "Customer Service Agent" doesn't just answer questions—it actively enhances the shopping experience. The interface maintains the familiar chat widget positioning, but notice the sophisticated capabilities underneath: real-time cart analysis ($42.97 total for soil products), contextual product recommendations based on what's already selected, voice interaction (indicated by the microphone icon), and seamless integration with the shopping experience.
The agent demonstrates proactive assistance, offering soil product recommendations that complement the fertilizers already in the cart. This isn't reactive support—it's anticipatory guidance. The chat knows your context (cart contents, shopping patterns) and uses that knowledge to provide genuinely helpful suggestions.
What makes this implementation particularly effective is its restraint. The chat doesn't try to replace the shopping interface—it augments it. Users can still browse products, manage their cart, and check out normally. The AI agent simply makes the experience smoother, like having a knowledgeable friend shopping alongside you.
This pattern succeeds because it separates interface familiarity from capability complexity. Users don't need to learn a new interface paradigm to access powerful AI capabilities. They just chat, as they've always done, but now the entity on the other end can actually understand context, anticipate needs, and provide intelligent assistance.
Widgets Within Chat: Linear Enhancement
Head AI showcases a sophisticated implementation of widgets within a conversational interface. As "the world's first AI Marketer," it demonstrates how interactive elements can transform a chat from simple Q&A into a comprehensive campaign builder.
The interface presents marketing channel strategies as selectable cards—Influencer marketing, Affiliate marketing, and Cold email campaigns. Each card isn't just a button; it's a mini-interface containing the strategy name, a brief description, and the goal metric (website traffic, sales, or leads). The orange selection indicators make the current choices immediately visible.
Below the channel selection, optional enterprise solutions appear as checkboxes, allowing users to layer additional capabilities onto their base strategy. The interface maintains conversational context—"Hi Angry, I've generated your personalized marketing strategies based on your input"—while providing rich interaction through visual elements.
What makes this implementation particularly effective is how it balances guidance with flexibility. The AI presents curated options based on the user's initial input (v.com appears to be their website), but users maintain control through visual selection. The "Generate" button in the top right promises to transform these selections into a full campaign.
The pattern reveals a key insight: widgets work best when they represent genuine choices rather than simple confirmations. Instead of asking users to type "influencer marketing" or "affiliate marketing," the interface presents the options visually with enough context to make informed decisions. This reduces cognitive load while maintaining user agency.
However, the linear nature still imposes limitations. Users can't easily compare different campaign configurations or see how choices interconnect. The interface shows the current step clearly but obscures the journey—both where they've been and where they're going.
Cursor for Professional Tools: AI in Domain-Specific Context
ReelPal demonstrates what happens when the "Cursor for X" pattern extends beyond code editing into professional creative tools. Just as Cursor revolutionized programming by embedding AI chat into the IDE, ReelPal embeds conversational AI directly into video editing workflows.
The interface maintains the familiar structure of professional video editing software—timeline at the bottom, preview window in the center, project files on the left. But notice the crucial addition: a collapsible AI panel on the right that provides context-aware assistance without disrupting the core editing experience.
The AI integration goes deeper than simple chat. When users request "generate a compelling video of the iconic superhero Batman," the AI doesn't just provide advice—it orchestrates actual editing operations. The timeline shows the AI-generated result with multiple tracks for music and voiceover, automatic clip selection and arrangement, and intelligent duration management (5 seconds in this example).
What makes this implementation particularly powerful is the preservation of professional control. The AI generates a complete edit, but every element remains fully editable. Users can adjust clip timing, swap music tracks, modify voiceover scripts, or completely override AI decisions. The system enhances expertise rather than replacing it.
The "Generate Media" panel reveals sophisticated capabilities: choosing between different AI models (Kting 2.1 Master), reference image uploads for style consistency, duration controls, and advanced settings for fine-tuning. This isn't a black box—it's a transparent tool that exposes its parameters while maintaining ease of use.
The pattern succeeds because it respects the professional's workflow. Video editors think in terms of timelines, tracks, and clips. The AI speaks this language, generating outputs that fit naturally into existing mental models. A request for "Batman video" becomes a properly structured timeline with appropriate music and voiceover—exactly what an editor would create manually, but in seconds rather than hours.
This approach—embedding AI into professional tools while preserving domain-specific interfaces—points toward a future where every professional application gains an AI collaborator that understands not just commands but context, workflow, and professional standards.
Split Screen: Dynamic Task Interfaces
Our team at H2A.DEV developed this split-screen prototype to explore a middle ground between full professional interfaces (like Cursor) and simple widgets. The implementation demonstrates how GTUI principles enable task-specific interfaces that generate dynamically while maintaining sophisticated interaction capabilities.
The left panel maintains the conversational foundation—users can type commands, see the agent's thinking process, and maintain context across multiple tasks. But unlike pure chat interfaces, the right panel manifests as a purpose-built interface for the current task. When creating social media content, it becomes a visual post editor. When analyzing data, it might transform into interactive charts. The interface adapts to the task, not the other way around.
In this Instagram example, notice how the same content request ("Create an Instagram post about meditation using meditation.png") generates both the visual preview and editable caption. The interface provides immediate visual feedback—users see exactly how their post will appear—while maintaining full editorial control through the caption editor below the image.
The split-screen pattern offers several advantages over pure chat. Visual context persists—you can see the Instagram post while refining the caption. Bidirectional interaction works naturally—edit the caption directly or ask the AI to regenerate it. The task flow remains visible—from initial request through interface generation to final posting.
Most importantly, this pattern scales across different tasks without requiring pre-built interfaces for every possibility. The same system that generates Instagram posts can create LinkedIn articles, Twitter threads, or YouTube descriptions. The interface generates based on need, not predetermined templates.
The character count (164/2200) and hashtag toggles show how task-specific functionality can emerge dynamically. These aren't generic form fields—they're Instagram-specific elements that appear because the task demands them. This is GTUI in action: the interface converses itself into existence based on what you're trying to achieve.
Headless: Pure Execution
At the extreme end of the interface spectrum lies the headless pattern—no GUI, no widgets, no visual feedback beyond terminal output. Our H2A.DEV team's video generation example demonstrates this pattern in its purest form, equivalent to Claude Code's -p parameter mode.
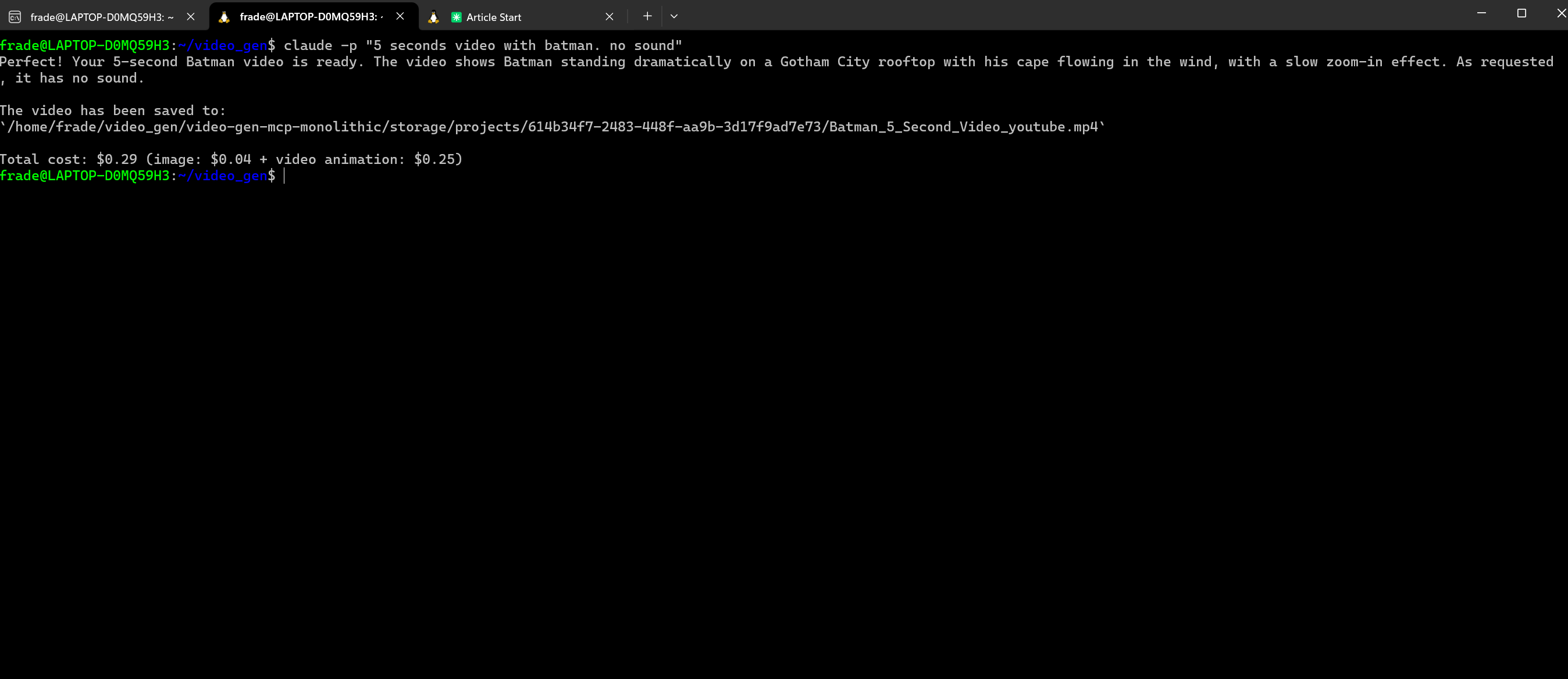
The command is stark in its simplicity: claude -p "5 seconds video with batman. no sound". No interface appears. No progress bars animate. No preview windows pop up. Yet within moments, a complete video materializes—Batman standing dramatically on a Gotham City rooftop, cape flowing in the wind, with a slow zoom-in effect, exactly as requested.
The output provides just essential information: confirmation of task completion, file location for retrieval, and cost breakdown ($0.29 total: $0.04 for image + $0.25 for video animation). This isn't minimalism for its own sake—it's recognition that sometimes the best interface is no interface at all.
Headless execution excels in specific scenarios. Well-defined tasks with clear parameters don't need visual negotiation. Automated workflows benefit from zero UI overhead. Expert users who know exactly what they want can skip the visual intermediaries. Batch processing becomes trivial when there's no interface to navigate.
But the pattern also reveals the importance of trust and expertise. Without visual feedback, users must trust the agent's interpretation. Without interactive refinement, the initial prompt must be precise. Without progress indicators, patience becomes necessary. The headless pattern works best when the agent is well-trained, the task is well-understood, and the user is well-informed.
This example perfectly illustrates the principle: for a mature agent handling a familiar task, the interface can disappear entirely. The communication layer collapses to its essence—pure intent transformed directly into execution. No chrome, no ceremony, just results.
The Pattern Language Emerges
Through our exploration of these seven interface patterns, a clear taxonomy emerges. Each pattern serves specific use cases, user types, and interaction models. Understanding when to apply each pattern becomes as important as understanding how to implement them.
Canvas interfaces excel when dealing with workflow visualization and multi-step processes. They transform abstract agent orchestration into spatial relationships that humans intuitively understand. Best for creative workflows, complex automations, and scenarios where seeing the whole picture matters more than individual steps.
Chat on a webpage leverages decades of user training in messaging interfaces. It works because it doesn't ask users to learn anything new—just to expect more from familiar interactions. Ideal for customer service, guided assistance, and augmenting existing web experiences.
Widgets within chat enhance linear conversations with moments of rich interaction. They reduce friction for common operations while maintaining the conversational flow. Perfect for guided processes, form-filling, and scenarios where visual selection beats textual description.
Professional tool integration (Cursor for X) respects domain expertise while adding AI capabilities. These implementations succeed by speaking the professional's language—timelines for video editors, code for developers, spreadsheets for analysts. Essential when users need both AI assistance and professional control.
Split-screen interfaces balance conversation with purpose-built tools. They maintain context while providing task-specific functionality, adapting to needs rather than forcing users into predetermined molds. Optimal for varied tasks within a single session and users who need both guidance and control.
Headless execution strips away all pretense, reducing interaction to pure command and response. When the task is clear and the agent is capable, why add unnecessary layers? Best for automation, expert users, and well-defined operations.
Implications for the Future
The diversity of these patterns confirms a crucial insight: there is no universal interface for AI interaction. Just as we don't use hammers to turn screws, we shouldn't force all AI interactions through a single interface metaphor. The future belongs to adaptive systems that can shift between patterns based on context, user expertise, and task requirements.
Consider how a single user might flow through multiple patterns in one session. They begin with a chat interface to explore possibilities, shift to a canvas view to design a workflow, use split-screen to refine specific elements, and finally execute headless once the process is perfected. The interface adapts to their journey from exploration to execution.
This pattern language also reveals the importance of the three-layer architecture. Every successful implementation—whether visual or textual, simple or complex—relies on the same foundation: world knowledge informing agent capabilities, communication layers adapting to user needs, and execution layers handling the actual work. The interface patterns are simply different expressions of this underlying structure.
Conclusion
As we witness the evolution from "autocomplete" to "auto-interface," we're seeing more than just technical progress. We're watching the emergence of a new design discipline—one that designs not interfaces but interface generators, not interactions but interaction patterns, not experiences but experience possibilities.
The interfaces we've examined—from youpac.dev's intuitive video canvas to our headless execution experiments—each represent a different philosophy about human-AI collaboration. Some emphasize visual clarity, others conversational flow. Some preserve professional workflows, others reimagine them entirely. But all share a common thread: they're built on the recognition that the interface must serve the interaction, not constrain it.
The most profound insight from this exploration is that these patterns aren't competing—they're composing. A mature AI ecosystem will fluidly combine these approaches, selecting the right pattern for each moment. Canvas when you need to see workflows, chat when you need guidance, widgets when you need quick inputs, professional integration when you need domain tools, split-screen when you need flexibility, and headless when you just need results.
As developers and designers, our task is no longer to choose the "best" interface pattern but to understand when each pattern serves users best. We must build systems intelligent enough to shift between patterns as naturally as humans shift between thinking modes—sometimes visual, sometimes verbal, sometimes procedural, always adaptive.
The future of human-AI interaction isn't about finding the perfect interface. It's about creating systems that generate perfect interfaces for each moment, each task, and each user. In this future, the question isn't "What interface should we build?" but "What interface does this moment demand?"
Welcome to the age of adaptive AI interfaces, where the communication layer doesn't just connect humans and agents—it transforms itself to make that connection as natural, efficient, and powerful as possible. The patterns are emerging. The language is forming. The future is generating itself, one interface at a time.